
Hello Sascha, can you introduce yourself and your work in the HRI-lab Sønderborg?
My name is Sascha Steinhoff. I am currently studying Web Communication Design at the SDU. My job at the HRI-lab is to maintain the website and to support scientists in the technical setup for surveys and to subsequently code the survey results.
Does survey coding include the analysis of the results?
No, it does not. Coding means that you classify answers given by the participants as either correct or incorrect. The scientist who designed the survey usually provides an answer key with correct sample answers for this purpose.
Why is coding a separate process? For me it would be more logical if the scientist did it together with the analysis.
This is right for simple surveys that have only a limited set of predefined answering options, like closed questions. This can easily be done by the scientists themselves without any external help.

An example for closed questions: The answers are strictly predefined, the participant can only choose but not change the option.
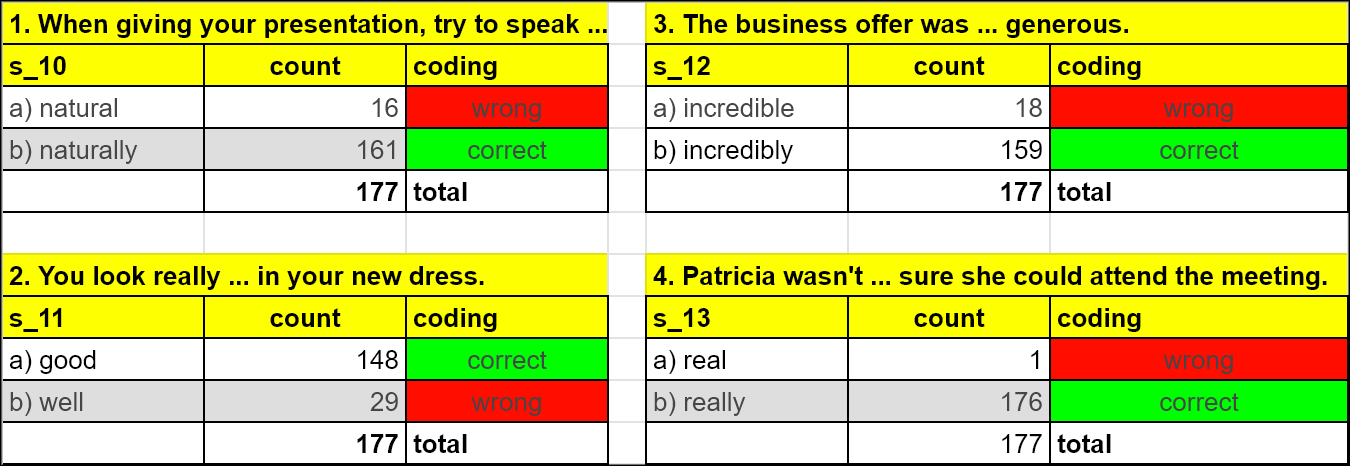
Coding the answers for closed questions is easy: The attribures "correct" and "wrong" can be directly assigned to the data records.
What do you do with open questions?
They need a different approach, because in most cases you need to to process the answers before you can code them. In this case the coding takes significant time and it can be technically challending as well.

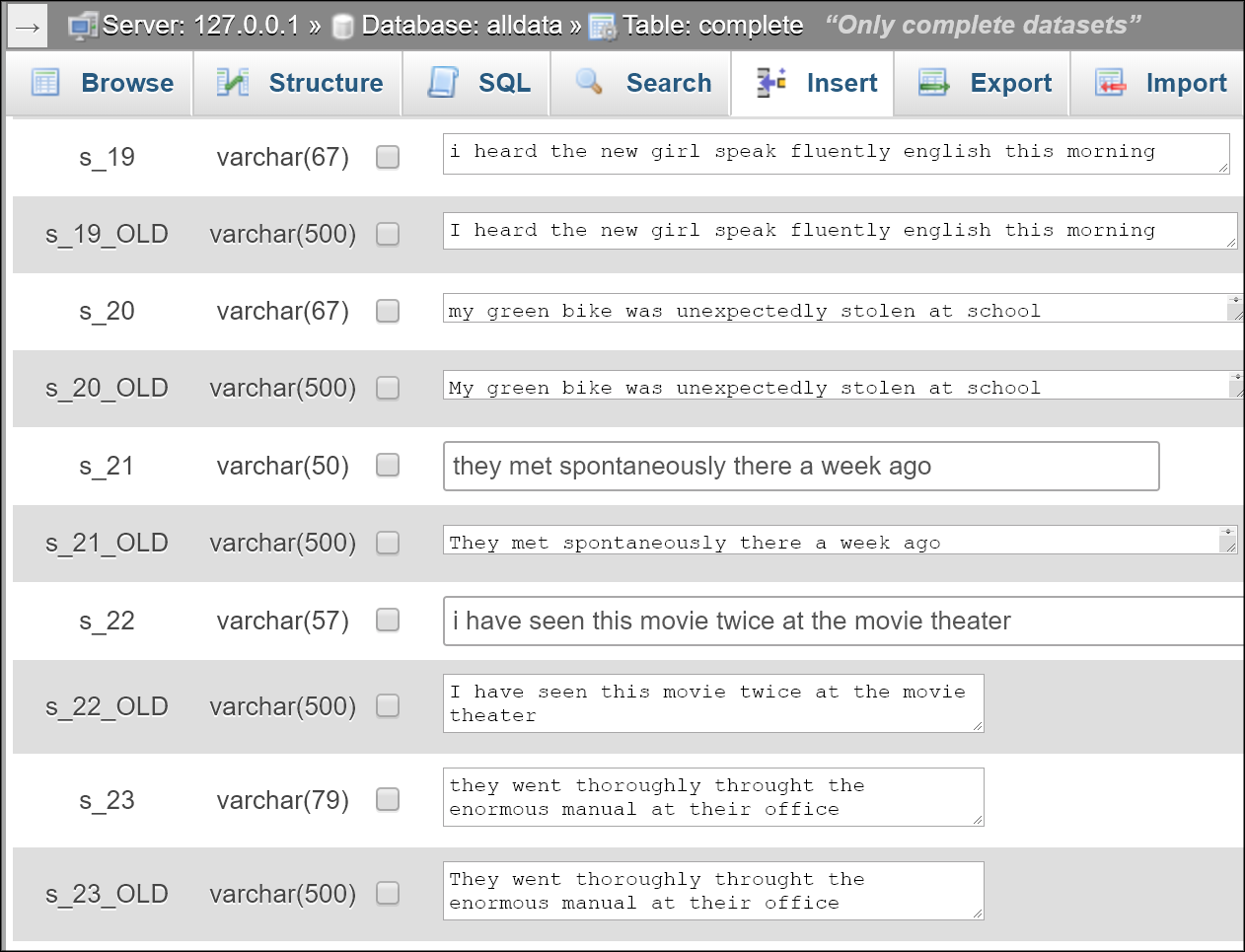
An example for open questions: Participants type the answer into a text field and this is prone to input errors.

This screenshot shows the standard solution (green) and a small selection of distinct answers that had been given by participants. For open questions each distinct answer needs to be coded manually and this can be tedious.
Ok, how would such a data coding work in practice?
First of all, you have to close the query for participants to avoid that more data is generated. Then you export the raw data records from the survey application. Survey tools like SurveyXact provide an export functionality for that. Next step is....
Sorry to interrupt you. But why is this export needed? Most survey tools have integrated functionalities for survey analysis. So no need to export the data and to use another tool, right?
Right, but only in the case of simple surveys where answers are strictly predefined. But this does not work for complex surveys where you have to manually code a multitude of answer options.

SurveyXact has built-in analysis features. These are useful for data that needs no further preparation.
What are the most common options to code a query?
The easiest method is to do everything in the survey application, like SurveyXact or LimeSurvey. But this works only for simple surveys where you don’t need to process the data records.
You have more options when using Excel, or any other spreadsheet application, in addition to the survey tool.
Exactly, the most powerful is to use the survey tool in combination with Excel and maybe even a database like MySQL. The database is really good in data processing and querying, but you still need Excel e.g. for charts or other reader-friendly data output.
What is your approach?
For me it worked best to export the full unfiltered set of raw data records, for example in CSV-format. CSV-data can be imported into many applications. The most popular tools are spreadsheet applications like Microsoft Excel, LibreOffice or Google Sheets.
Which one of these do you use?
None of these for the coding. I prefer to import the CSV-data into a MySQL database for that purpose. MySQL is less user friendly than Excel and the like. But it has a better performance with large datasets and it offers more powerful ways to query data, especially when interlinking different data tables.
MySQL is a powerful open source database and ideally suited to process even large sets of data records. Here it runs locally on XAMPP.
Does it matter which application you choose?
I don’t think so. My recommendation would be to use an application that you are familiar with and that you use often. I started with Google Sheets and Excel, but if you need to process large datasets you’ll most likely need Add-Ons or scripting. Add-Ons are comfortable to use but not always stable, and scripting in Excel is not exactly self-explaining in my opinion.
For this reason I later switched to the database MySQL which works well for me. SQL is a universal language and some database know-how is useful for many situations. That’s the reason why I personally prefer to work with databases when processing large data records. But as said before: You could do everything in Excel as well.
Do you have a recommendation which application is best for certain tasks?
I think the best way to find out is to work productively with data and to try different applications. There is no better way. You’ll probably end up with one favorite application that you like to work with and that covers most tasks.
Ok, once you have imported the data, what do you do?
First of all you have to locate and eliminate obvious trash data records. Almost any survey has a couple of participants who don't seriously answer the questions and insert obvious nonsense like “blabla” instead of a proper answer.
The same applies if participants fill out the questionnaire in another language than asked for or participants filled in just a single letter or number in order to proceed to the next question. All this data needs to be filtered out as early as possible.
How much time would you need for the coding of a survey?
That depends on the questions. Closed questions are easy to code because you simply assign the solution to the answers. Here is no need to process data or to interpret answers, you simply mark them as correct or wrong. With open questions, it is a whole different issue. You have to check each answer individually for open questions and that takes time.
Why don’t you simply assign the sample solution on open questions? If this works with closed questions, why not with open questions?
Automatically classifying answers would classify many answer as incorrect that are in fact correct. Every spelling error, every unexpected punctuation mark and every superfluous space character will be misinterpreted as a wrong answer. Even if the answer itself is syntactically correct.
That sounds like a lot of boring manual work. Is there a way to speed up things?
You can standardize the data. This will save you some work in the coding process.
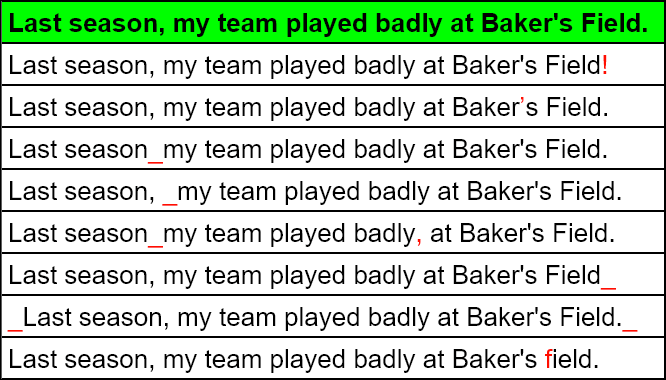
Typing errors in user input, the use of different punctation marks or blanks will lead to a mismatch with the provided standard solution (standard solution in green, all deviations marked in red).
How would data standardization work?
It depends on the question. We often have questions that are testing word order in sentences. Meaning that e.g. punctuation and upper or lower cases are not important. In this case I process the raw data records like this:
- Replace all punctuation marks (like “.,;:!?”) with blanks
- Set all words to lowercase
- Replace all double spaces with single spaces
- Trim the data by removing space characters from the start and end of each data record
This is of course just the basic standardization. You have to look at individual data records to see if more optimization is possible. Fixing common misspellings is e.g. another possible method for data standardization.
What is the next step after data standardization?
Many answering options would appear more than once. Consequently, you can save time by filtering out all distinctive answers to a question and to code only these. I usually create a separate table for all distinct answers.
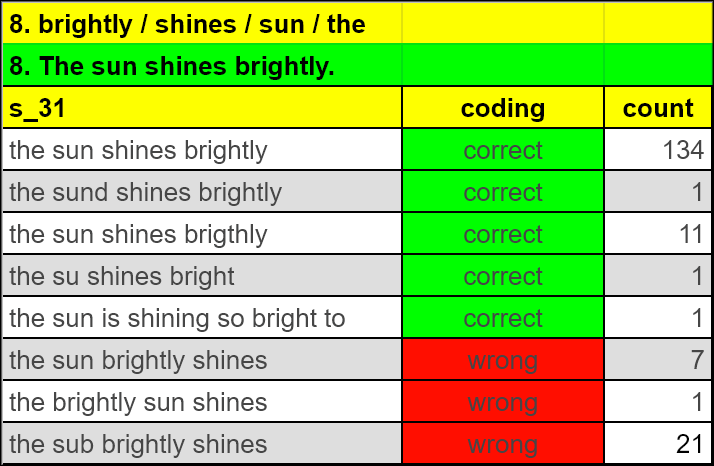
A separate coding table provides the coding for each distinct answer that had been inserted by participants. This is an efficient way to code ansewrs because many are used more than once (see column "count").
Why do you use a separate table for the coding of each answer?
Because it is a central place to code each distinct answering option only once. Once this is done, you can easily assign the coding to the full table with all data records of the survey.
Using a separate table for the coding of answers is both faster and more accurate than separately coding the answer for each data records.
Can you give a practical example where you used this approach?
In a recent study, we made people fill out a language proficiency test with the focus on word order. Before data standardization, we had about 80 different answers for a single question. Data standardization reduced that to about 50 distinct answers. These had to be coded manually, which still was much work. But it was much faster than manually coding the questions for each data record of the 177 participants with often repetitive answers.
How would you hand over the results of your coding to the researchers for the subsequent analysis?
I usually export the data from the MySQL database and upload it to Google Sheets. Google has a simliar functionality as a locally installed Excel or LibreOffice, but you can simultaneously work on it with several editors in different location. I think Google Sheet is perfect for collaborative work, like e.g. checking the results of the coding in a research team.
Google Sheets provide a convenient way for data sharing and collaborative work
Are there any reasons not to use Google Sheets?
Sure, I would never use Google Sheets for strictly confidential or groundbreaking research. Data security and privacy is not always guaranteed with cloud services.
Is there anything that you should consider when setting up and coding a survey?
It is nowadays technically very easy to produce big data records that are so comprehensive that you can have a hard time coding them. Not even speaking of the subsequent analysis. For this reason it is recommendable to invest sufficient time in the initial setup of the survey to produce clean and manageable data.
No more questions from my side, thank you for the interview.
Thank you, Selina.
This interview had been conducted by Selina Sara Eisenberger in May 2019.